Any private-coin randomized protocol  that computes
that computes  with an error probability of at most
with an error probability of at most  cannot use less than some multiple of
cannot use less than some multiple of  bits in the worst case.
bits in the worst case.
Invoke Newman’s Theorem
 = R^{pub}_{\epsilon-\delta} (DISJ_n) + O(\log n + \log \delta^{-1})") .
.
Since  asymptotically, it suffices to show that
asymptotically, it suffices to show that
 = \Omega (\sqrt{n})") , for
, for 
Now recall Yao’s Lemma:
 \geq \max_{\mu}\{D^{\mu}_{\epsilon}(DISJ_n)")
which allows us to reduce the problem to coming up with a probability distribution  over
over  such that any deterministic protocol which errs with probability of at most on any input according to communicates at least some multiple of bits in the worst case.
such that any deterministic protocol which errs with probability of at most on any input according to communicates at least some multiple of bits in the worst case.
One initial thought worth investigating is what happens when if  uniform. Suppose Alice and Bob both choose any subset of
uniform. Suppose Alice and Bob both choose any subset of ![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=000000&s=1 "[n]") uniformly. Then the probability that they choose disjoint subsets is
uniformly. Then the probability that they choose disjoint subsets is ^n") , which goes to 0 as
, which goes to 0 as  grows large. So a protocol that just outputs 0 (they are NOT disjoint) can be made to have an arbitrarily small error asymptotically, which means that we only get an
grows large. So a protocol that just outputs 0 (they are NOT disjoint) can be made to have an arbitrarily small error asymptotically, which means that we only get an ") bound by using the uniform distribution. We are not satisfied.
bound by using the uniform distribution. We are not satisfied.
Instead, consider the following product distribution: Alice and Bob cannot possibly pick a subset of whose size is different that and they pick subsets of size with uniform distribution. So  , where:
, where:
 = \rho(X) = \left\{ \begin{array}{ll} \!\! \frac{1}{\binom{n}{\sqrt{n}}}, &|X| = \sqrt{n}\\ \!\! 0, &\text{otherwise}\end{array}\right.")
In this case, the probability that Alice and Bob choose disjoint subsets is:
^{\sqrt{n}} \approx \frac{1}{e}")
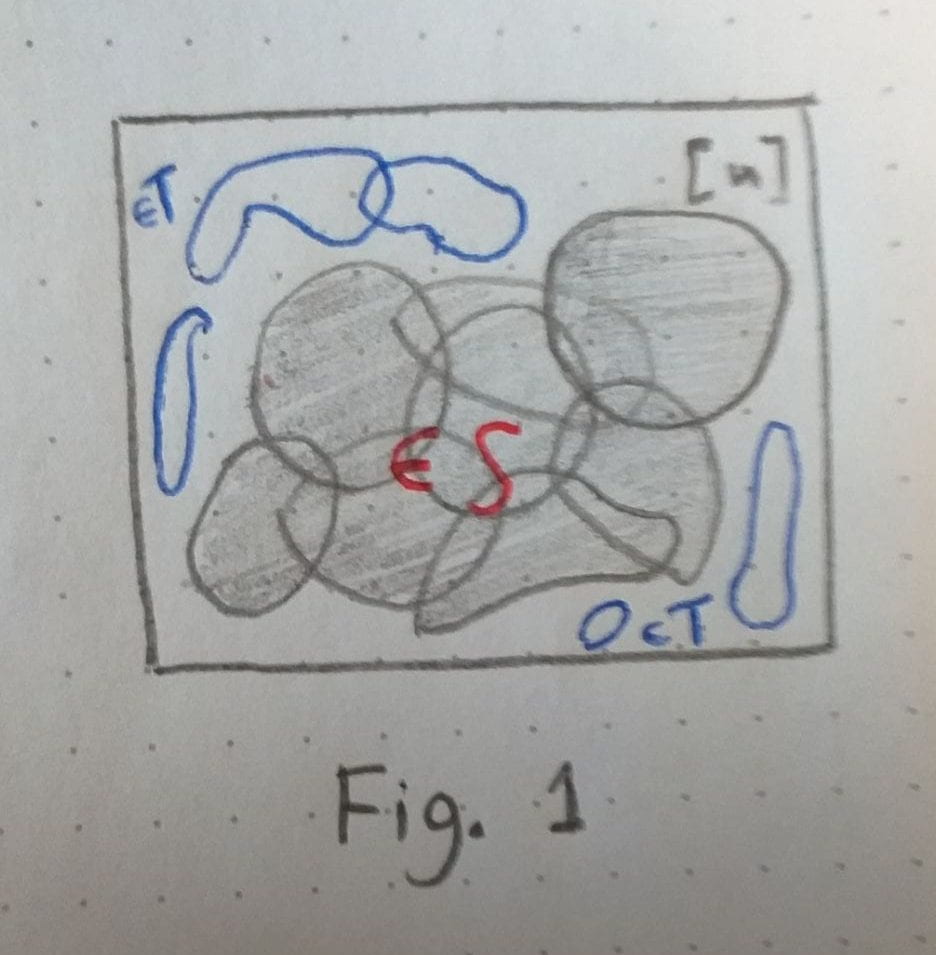
We will show that any deterministic protocol that, under , errs with a probability of at most in calculating , uses at least some factor of in the worst case.
The intuition is as follows: Let be the ") protocol with the minimum communication complexity. partitions
protocol with the minimum communication complexity. partitions  into rectangles, corresponding to its leaves. For each rectangle, answers in the same way in the question of whether the two input subsets are disjoint or not.
into rectangles, corresponding to its leaves. For each rectangle, answers in the same way in the question of whether the two input subsets are disjoint or not.
However, some of these rectangles may be corrupted. In other words, the protocol may output that the input sets are disjoint, when in fact they are not. Let’s look at 1-rectangles. That is, rectangles in which the protocol answers YES, they are disjoint (1). We know that errs with a probability of at most . Therefore, all of its rectangles have small corruption. Specifically, if  is an 1-rectangle, then
is an 1-rectangle, then
=0\,|,\, (x,y) \in R\} \leq \epsilon")
The figure below illustrates why that is.
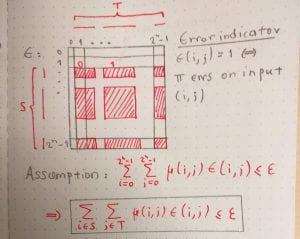
We show that exactly because the rectangles of cannot be too corrupted, they have to be small in size (their measure according to is small). This will imply that there are many of them and so we will have a lower bound to the communication complexity.
To elaborate further on this, let  be the maximum -measure of any 1-rectangle of . If we suppose for the purposes of contradiction that
be the maximum -measure of any 1-rectangle of . If we suppose for the purposes of contradiction that  \leq \alpha\sqrt{n}") for some
for some  , then the number of 1-rectangles is bounded above by the number of leaves of , which in turn is bounded above by
, then the number of 1-rectangles is bounded above by the number of leaves of , which in turn is bounded above by  .
.
 \leq 2^{\alpha\sqrt{n}}A")
And so  . In other words, if the communication complexity of is small, there must be a big 1-rectangle. And that rectangle has low corruption. We prove that this is impossible, acquiring a contradiction.
. In other words, if the communication complexity of is small, there must be a big 1-rectangle. And that rectangle has low corruption. We prove that this is impossible, acquiring a contradiction.
We prove the following Lemma (I):
“If  is a 1-rectangle of ,
is a 1-rectangle of ,
then either  or
or  has to be at most
has to be at most  for some constant
for some constant  .”
.”
After establishing this, if we let  be a 1-rectangle of and assume WLOG that
be a 1-rectangle of and assume WLOG that  , then
, then  by Lemma I, and so
by Lemma I, and so
 = \sum\limits_{s\in S, t\in T} \mu(s,t) = \left(\sum\limits_{s\in S}\lambda(s)\right)\left(\sum\limits_{t\in T} \rho(t)\right) \leq 1\cdot \frac{|T|}{\binom{n}{\sqrt{n}}} \leq 2^{-c\sqrt{n}}") ,
,
which implies that every 1-rectangle  must be small, thus giving us our contradiction.
must be small, thus giving us our contradiction.
Heading over to the proof of Lemma I, we first two simplifying assumptions:
- S is large (we will formalize this below but if S were small then our lemma holds vacuously).
- All the subsets of
![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=000000&s=0 "[n]") lying in
lying in  and
and  have size
have size  . There is 0 probability of getting subsets of size
. There is 0 probability of getting subsets of size  as inputs, so Alice and Bob can modify
as inputs, so Alice and Bob can modify  to immediately reject such input cases so that we don’t have to worry about its behavior on them.
to immediately reject such input cases so that we don’t have to worry about its behavior on them.
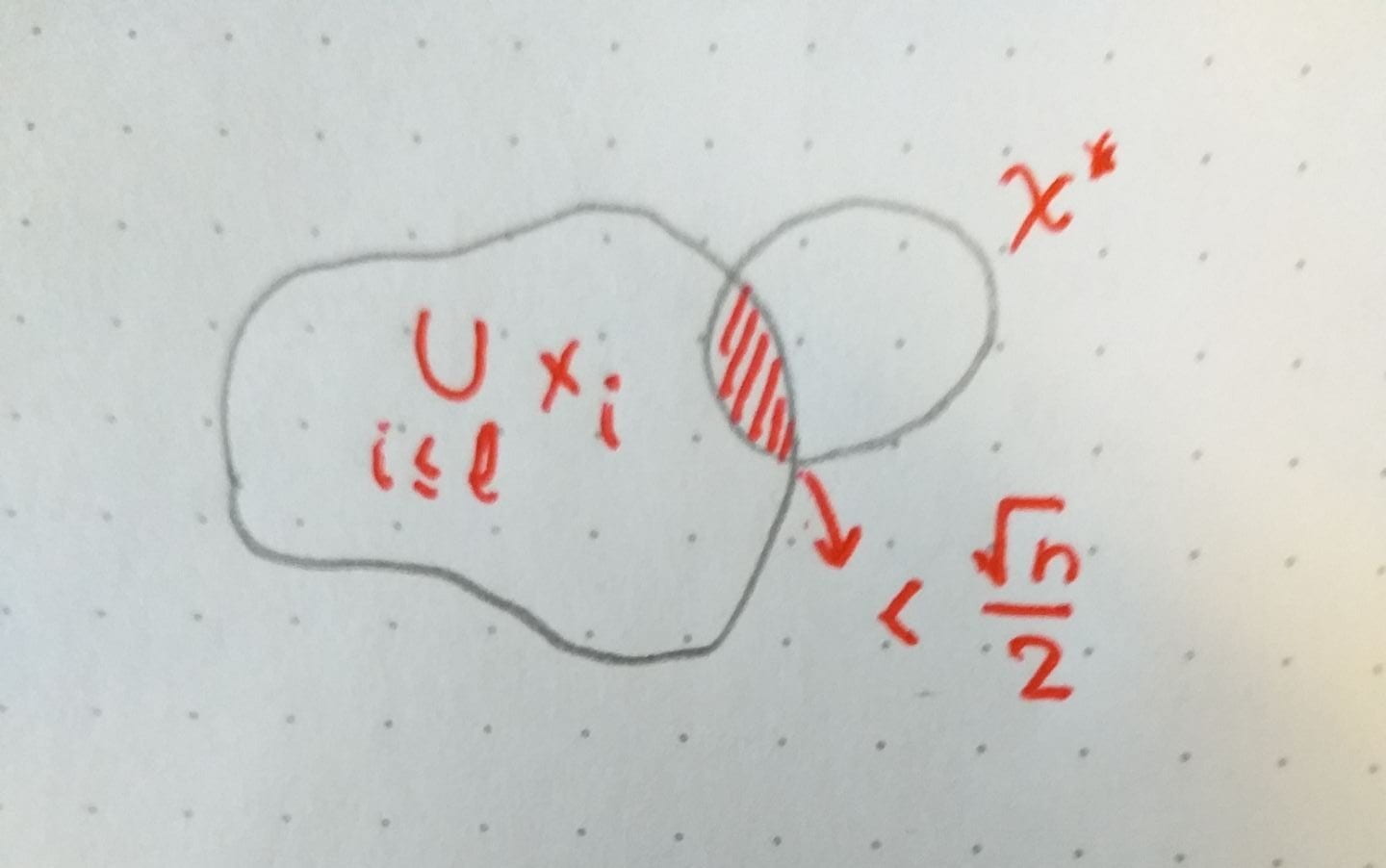
Intuition: If is large, then its sets must span a large fraction of . There cannot exist too many sets disjoint with the sets of then. So is small. This is illustrated in the figure below:
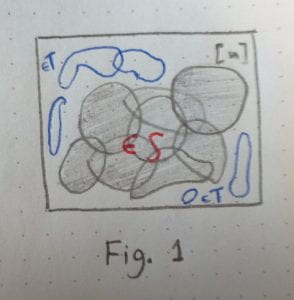
We shall start by proving that the span of the elements of has to be big. This is the following Lemma, which could be stated without any relation to our communication complexity investigations:
LEMMA II: Let  be a collection of subsets of size of . Then there exists some
be a collection of subsets of size of . Then there exists some  such that if
such that if  , then for
, then for  , there exist sets
, there exist sets  such that
such that  it holds that
it holds that

Proof
We show that if we pick any  sets
sets  , we can find another set
, we can find another set  that shares less that
that shares less that  elements with the
elements with the  sets we picked.
sets we picked.
In other words:

This gives us an incremental procedure of finding the collection  : Every new set we add has less than common elements with all the previous sets chosen and this is exactly what we want to prove. This is shown in the figure below:
: Every new set we add has less than common elements with all the previous sets chosen and this is exactly what we want to prove. This is shown in the figure below:



for large enough  , where the constant is obtained through Stirling’s approximation
, where the constant is obtained through Stirling’s approximation  = n\log_2 n - n\log_2 e + O(log_2 n)") . This concludes the proof of Lemma (II) because we have found that there must exist some such that
. This concludes the proof of Lemma (II) because we have found that there must exist some such that  .
.
Note that this Lemma implies that spans a large portion of  . Since each one of the
. Since each one of the  -s adds at least another
-s adds at least another  new elements, we have that
new elements, we have that  , meaning that spans at least one sixth of , which is a good fraction for our purposes.
, meaning that spans at least one sixth of , which is a good fraction for our purposes.
Let’s now see exactly how having a large span forces to be small. The main idea lies in the fact that has low corruption, so we seek sets that are disjoint with most sets in and that number is bounded above because of the large span property.
Let  to be the set of elements in which are such that they intersect with a fraction of at most
to be the set of elements in which are such that they intersect with a fraction of at most  of the sets of . We must have
of the sets of . We must have  , as if that wasn’t the case, there would be more than
, as if that wasn’t the case, there would be more than 
 s of
s of  in and, because both and consist of rectangles of size which we uniformly sample, that would violate our low-corruption hypothesis.
in and, because both and consist of rectangles of size which we uniformly sample, that would violate our low-corruption hypothesis.
Applying Lemma II to , we get that there exists some constant such that if  – implying the largeness of :
– implying the largeness of :  ) – then there exists a sub-collection of with
) – then there exists a sub-collection of with  whose span over is big as we saw before.
whose span over is big as we saw before.
So let’s assume that as dictated above and let us take  . Now also consider the sub-collection of consisting of sets that have an intersection with a fraction of at most
. Now also consider the sub-collection of consisting of sets that have an intersection with a fraction of at most  elements of
elements of  . Then
. Then  would have to contain at least half of the elements of –
would have to contain at least half of the elements of –  – as otherwise there would be more than
– as otherwise there would be more than 
 in , contradicting once again our low-corruption hypothesis.
in , contradicting once again our low-corruption hypothesis.
It is important to conceptually notice here how the low-corruption hypothesis forces large parts of and to not overlap with each other too much! So we seek sets that are mostly disjoint among the two groups. And the big span of constrains our options greatly. We show that there cannot be that many sets by bounding from above.
For each set  in , there are at most
in , there are at most  sets in which intersect it. So there must exist
sets in which intersect it. So there must exist k") sets
sets k}}") in that all don’t intersect it, which limits how many elements can possibly have. That is we must have that
in that all don’t intersect it, which limits how many elements can possibly have. That is we must have that ![y \subseteq [n] \setminus \cup_j x_{i_j}](https://s0.wp.com/latex.php?latex=y+%5Csubseteq+%5Bn%5D+%5Csetminus+%5Ccup_j+x_%7Bi_j%7D&bg=ffffff&fg=000000&s=0 "y \subseteq [n] \setminus \cup_j x_{i_j}") and knowing that each
and knowing that each  brings in at least new elements, we must have
brings in at least new elements, we must have ![\left|[n] \setminus \cup_j x_{i_j}\right| \leq n - (1-4\epsilon)k\frac{\sqrt{n}}{2} \leq \frac{8n}{9}](https://s0.wp.com/latex.php?latex=%5Cleft%7C%5Bn%5D+%5Csetminus+%5Ccup_j+x_%7Bi_j%7D%5Cright%7C+%5Cleq+n+-+%281-4%5Cepsilon%29k%5Cfrac%7B%5Csqrt%7Bn%7D%7D%7B2%7D+%5Cleq+%5Cfrac%7B8n%7D%7B9%7D&bg=ffffff&fg=000000&s=0 "\left|[n] \setminus \cup_j x_{i_j}\right| \leq n - (1-4\epsilon)k\frac{\sqrt{n}}{2} \leq \frac{8n}{9}") assuming that
assuming that  . That doesn’t seem like a lot: all we said is that must be drawn from a fraction of
. That doesn’t seem like a lot: all we said is that must be drawn from a fraction of  -ths of the universe. But it provides us with the bound we needed.
-ths of the universe. But it provides us with the bound we needed.
The number of possible -s is at most:
k}\binom{8n/9}{\sqrt{n}} = \binom{\sqrt{n}/3}{4\epsilon\sqrt{n}/3}\binom{8n/9}{\sqrt{n}} < 2^{-1-c''\sqrt{n}}\binom{n}{\sqrt{n}}") ,
,
where  is a constant given again by Stirling’s approximation.
is a constant given again by Stirling’s approximation.
So  . Taking
. Taking ") concludes our proof.
concludes our proof.


^* = T^* + U^*")
^* = \bar{c}T^*")
^* = U^* T^*")
^* = T")

, y \rangle = \langle x, T^*(y) \rangle")

, (t_2, y_2), . . . , (t_n, y_n)")
^2")


![A = \left [ \begin{array}{cc} t_1 & 1 \\ t_2 & 1 \\ . & .\\.&.\\.&.\\ \\ t_n & 1 \end{array} \right ], x = \left[\begin{array}{cc}c\\d\end{array}\right]](https://s0.wp.com/latex.php?latex=A+%3D+%5Cleft+%5B+%5Cbegin%7Barray%7D%7Bcc%7D+t_1+%26+1+%5C%5C+t_2+%26+1+%5C%5C+.+%26+.%5C%5C.%26.%5C%5C.%26.%5C%5C+%5C%5C+t_n+%26+1+%5Cend%7Barray%7D+%5Cright+%5D%2C+x+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Dc%5C%5Cd%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "A = \left [ \begin{array}{cc} t_1 & 1 \\ t_2 & 1 \\ . & .\\.&.\\.&.\\ \\ t_n & 1 \end{array} \right ], x = \left[\begin{array}{cc}c\\d\end{array}\right]")
![y = \left[\begin{array}{cc}y_1\\y_2\\.\\.\\.\\y_n\end{array}\right]](https://s0.wp.com/latex.php?latex=y+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7Dy_1%5C%5Cy_2%5C%5C.%5C%5C.%5C%5C.%5C%5Cy_n%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "y = \left[\begin{array}{cc}y_1\\y_2\\.\\.\\.\\y_n\end{array}\right]")








 = rank (A)")









 \rangle = 0")

^{-1} A^* y")
, b \in F^m")

to
.
. So, if
satisfies
, then
.


 = (R(L_A^*))^{\perp}")
 be a symmetric matrix with eigenvalues
be a symmetric matrix with eigenvalues  . Then:
. Then: = k}} \min\limits_{\substack{x\in S \\ x\neq 0}} \frac{x^T M x}{x^T x}") .
. be an orthonormal eigenbasis of
be an orthonormal eigenbasis of  belongs to the eigenspace of
belongs to the eigenspace of  . Then we can write
. Then we can write  , where
, where  .
.![x^T M x = x^T M \left(\sum\limits_{i=1}^n c_i y_i\right) = x^T \left[\sum\limits_{i=1}^n c_i (M y_i) \right] = x^T \left (\sum\limits_{i=1}^n c_i \mu_i y_i\right) = \sum\limits_{i=1}^n c_i^2 \mu_i](https://s0.wp.com/latex.php?latex=x%5ET+M+x+%3D+x%5ET+M+%5Cleft%28%5Csum%5Climits_%7Bi%3D1%7D%5En+c_i+y_i%5Cright%29+%3D+x%5ET+%5Cleft%5B%5Csum%5Climits_%7Bi%3D1%7D%5En+c_i+%28M+y_i%29+%5Cright%5D+%3D+x%5ET+%5Cleft+%28%5Csum%5Climits_%7Bi%3D1%7D%5En+c_i+%5Cmu_i+y_i%5Cright%29+%3D+%5Csum%5Climits_%7Bi%3D1%7D%5En+c_i%5E2+%5Cmu_i&bg=ffffff&fg=000000&s=0 "x^T M x = x^T M \left(\sum\limits_{i=1}^n c_i y_i\right) = x^T \left[\sum\limits_{i=1}^n c_i (M y_i) \right] = x^T \left (\sum\limits_{i=1}^n c_i \mu_i y_i\right) = \sum\limits_{i=1}^n c_i^2 \mu_i") , as our basis is orthonormal.
, as our basis is orthonormal. we have that
we have that .
.") , then
, then  and using our step 2, we get:
and using our step 2, we get:

") of dimension
of dimension  .
.  has dimension at least 1. So:
has dimension at least 1. So:
 for any
for any  , we get that:
, we get that:
 and let
and let  be a linear transformation. Then there exists a unique vector
be a linear transformation. Then there exists a unique vector  such that
such that  = \langle x,y \rangle") for all
for all  .
. which is such that
which is such that , y\rangle = \langle x, T^*(y)\rangle") is called the adjoint of
is called the adjoint of  be an orthonormal basis for
be an orthonormal basis for ![[T^*]_\beta = [T]_\beta^*](https://s0.wp.com/latex.php?latex=%5BT%5E%2A%5D_%5Cbeta+%3D+%5BT%5D_%5Cbeta%5E%2A&bg=ffffff&fg=000000&s=0 "[T^*]_\beta = [T]_\beta^*") .
.^*")
 be a base for
be a base for }u_i") .
. := \langle x,y\rangle") . For
. For ![i \in [n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bn%5D&bg=ffffff&fg=000000&s=0 "i \in [n]") we have:
we have:  = \langle u_i, \sum\limits_{j=1}^n \overline{g(u_j)}u_j \rangle = \sum\limits_{j=1}^n g(u_j) \langle u_i, u_j \rangle = g(u_i)") . Since
. Since  and
and  agree on every element of
agree on every element of  = \langle T(x), y \rangle") . It is easy to see that
. It is easy to see that  such that
such that  = \langle x, y^* \rangle") . Defining
. Defining  = y^*") gives us the adjoint. Linearity and uniqueness follow easily.
gives us the adjoint. Linearity and uniqueness follow easily.![([T^*]_\beta)_ij = \langle T^*(u_j), u_i \rangle = \overline{\langle T(u_i), u_j \rangle} = [T_\beta]^*](https://s0.wp.com/latex.php?latex=%28%5BT%5E%2A%5D_%5Cbeta%29_ij+%3D+%5Clangle+T%5E%2A%28u_j%29%2C+u_i+%5Crangle+%3D+%5Coverline%7B%5Clangle+T%28u_i%29%2C+u_j+%5Crangle%7D+%3D+%5BT_%5Cbeta%5D%5E%2A&bg=ffffff&fg=000000&s=0 "([T^*]_\beta)_ij = \langle T^*(u_j), u_i \rangle = \overline{\langle T(u_i), u_j \rangle} = [T_\beta]^*") .
.
 steps?”
steps?” be a function. We understand
be a function. We understand^k\times(\{0,1\}^n)^k\rightarrow\{0,1\}^k") ,
,,(y_1, . . . ,y_k)) = (g(x_1,y_1), . . . ,g(x_k,y_k))")
 = kD(g)") ?
? for which a protocol exists that computes
for which a protocol exists that computes  with less communication than
with less communication than  . Alice has a set
. Alice has a set ![S\subset [n]](https://s0.wp.com/latex.php?latex=S%5Csubset+%5Bn%5D&bg=ffffff&fg=000000&s=0 "S\subset [n]") of size
of size  . Bob has no input.
. Bob has no input. \right\rceil") bits, because the elements
bits, because the elements  can never be the minimum of
can never be the minimum of ![P \subset [n]](https://s0.wp.com/latex.php?latex=P+%5Csubset+%5Bn%5D&bg=ffffff&fg=000000&s=0 "P \subset [n]") whose cardinality is at most
whose cardinality is at most  . Thus, letting
. Thus, letting ![S = [n] - P](https://s0.wp.com/latex.php?latex=S+%3D+%5Bn%5D+-+P&bg=ffffff&fg=000000&s=0 "S = [n] - P") breaks the protocol.
breaks the protocol.![S_1, . . . , S_k \subset [n],\, |S_i| = n/2](https://s0.wp.com/latex.php?latex=S_1%2C+.+.+.+%2C+S_k+%5Csubset+%5Bn%5D%2C%5C%2C+%7CS_i%7C+%3D+n%2F2&bg=ffffff&fg=000000&s=0 "S_1, . . . , S_k \subset [n],\, |S_i| = n/2") , can output a
, can output a ") such that
such that ![s_i \in S_i\,\forall i \in [k]](https://s0.wp.com/latex.php?latex=s_i+%5Cin+S_i%5C%2C%5Cforall+i+%5Cin+%5Bk%5D&bg=ffffff&fg=000000&s=0 "s_i \in S_i\,\forall i \in [k]") . The way that protocol works is the following:
. The way that protocol works is the following:![Q \subset [n]^k](https://s0.wp.com/latex.php?latex=Q+%5Csubset+%5Bn%5D%5Ek&bg=ffffff&fg=000000&s=0 "Q \subset [n]^k") of
of ") with size
with size  which is such that for any sequence
which is such that for any sequence ![S_1, . . . , S_k \subset [n],\,|S_i| = n/2](https://s0.wp.com/latex.php?latex=S_1%2C+.+.+.+%2C+S_k+%5Csubset+%5Bn%5D%2C%5C%2C%7CS_i%7C+%3D+n%2F2&bg=ffffff&fg=000000&s=0 "S_1, . . . , S_k \subset [n],\,|S_i| = n/2") , there exists an element
, there exists an element  which is such that
which is such that ![q_i \in S_i\,\forall i \in [k]](https://s0.wp.com/latex.php?latex=q_i+%5Cin+S_i%5C%2C%5Cforall+i+%5Cin+%5Bk%5D&bg=ffffff&fg=000000&s=0 "q_i \in S_i\,\forall i \in [k]") . Let us call this statement Lemma I and we will prove it below. Alice finds
. Let us call this statement Lemma I and we will prove it below. Alice finds  \ll k\left\lceil \log_2\left(\frac{n}{2} +1\right)\right\rceil") bits of communication.
bits of communication. times: “Choose
times: “Choose ![S_1, . . . , S_k \subset [n], \,|S_i| = n/2](https://s0.wp.com/latex.php?latex=S_1%2C+.+.+.+%2C+S_k+%5Csubset+%5Bn%5D%2C+%5C%2C%7CS_i%7C+%3D+n%2F2&bg=ffffff&fg=000000&s=0 "S_1, . . . , S_k \subset [n], \,|S_i| = n/2") , what is the probability that for all
, what is the probability that for all ![i \in [k]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5Bk%5D&bg=ffffff&fg=000000&s=0 "i \in [k]") such that
such that  ?
? for all
for all ^{k}") . Therefore, the probability that for some
. Therefore, the probability that for some ^{k}") . So the probability that this happens for all
. So the probability that this happens for all ^{k})^{|Q|} \leq e^{-(\frac{1}{2})^k|Q|}")
 , the
, the ^k|Q|} = 2^{nk}e^{-nk} < 1") and so our proof concludes.
and so our proof concludes. , based on the fact that we can extract a monochromatic cover for
, based on the fact that we can extract a monochromatic cover for ") bits of communication.
bits of communication. monochromatic rectangles, then the inputs to
monochromatic rectangles, then the inputs to  monochromatic rectangles.”
monochromatic rectangles.”^2") bits communication, which finally yields that
bits communication, which finally yields that ") .
. , there exists a rectangle
, there exists a rectangle  of the inputs from
of the inputs from ^{2n\cdot 2^{l/k}} \leq 2^{2n}\cdot e^{-2^{-l/k}\cdot 2n2^{l/k}} = 2^{2n} \cdot e^{-2n} < 1")
^k\times(\{0,1\}^n)^k") can be covered by
can be covered by  has a lot of elements.
has a lot of elements. covering at least
covering at least  inputs from
inputs from  . Now, project
. Now, project  -th coordinate by retaining only the
-th coordinate by retaining only the  \in \{0,1\}^n\times \{0,1\}^n\,:\, \exists (a,b) \in R' \rightarrow a_i = x \wedge b_i = y\}")
 is a rectangle because
is a rectangle because  , and so
, and so
 , which proves our claim and finishes our theorem.
, which proves our claim and finishes our theorem.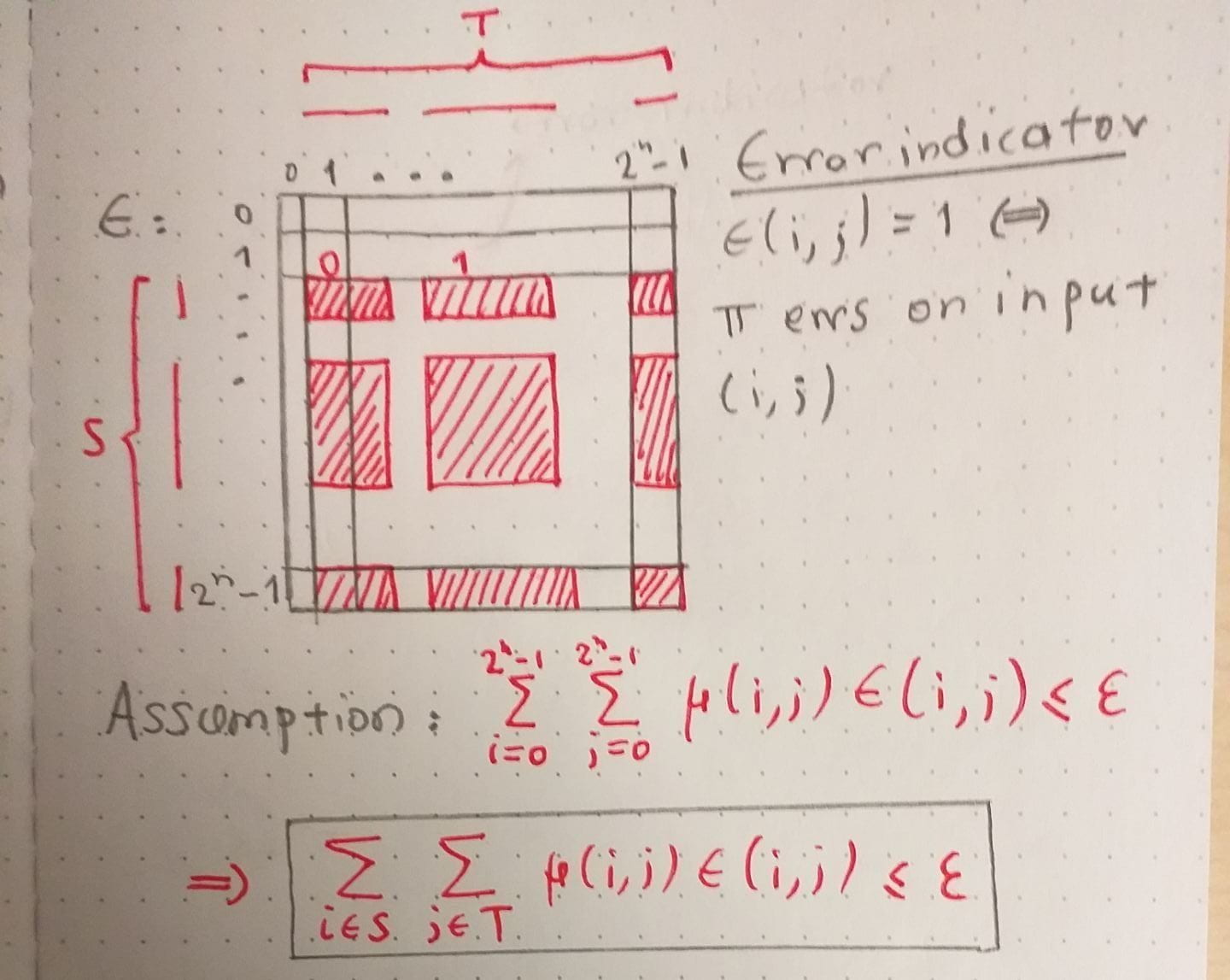
 be a sequence of real numbers so that
be a sequence of real numbers so that  is conditionally convergent (it converges but not absolutely). Then if we let
is conditionally convergent (it converges but not absolutely). Then if we let  , there exists a permutation
, there exists a permutation  of
of  such that
such that } = M")
^{n+1}}{n}") . We know this series converges to
. We know this series converges to ") , through Taylor’s series but the series
, through Taylor’s series but the series  is the harmonic series and diverges. So our series is conditionally convergent. But observe that we can rearrange the terms of the infinite sum so that the series converges to the half of itself:
is the harmonic series and diverges. So our series is conditionally convergent. But observe that we can rearrange the terms of the infinite sum so that the series converges to the half of itself: + \left(\frac{1}{3}-\frac{1}{6} - \frac{1}{8}\right) + \left(\frac{1}{5} - \frac{1}{10} - \frac{1}{12}\right) + \cdots = \sum\limits_{n=1}^{\infty}\left(\frac{1}{2n-1}-\frac{1}{4n-2} - \frac{1}{4n}\right) = \sum\limits_{n=1}^{\infty}\frac{1}{4k(2k-1)} = \frac{1}{2}ln(2)")
 .
. , there exists a rearrangement
, there exists a rearrangement  such that
such that and
and  ,
, is the sequence of partial sums of the rearranged sequence.
is the sequence of partial sums of the rearranged sequence. . In case there is confusion about the
. In case there is confusion about the  and
and  notation, recall that these signify the limit superior and limit inferior of a sequence, which are limiting bounds on a sequence (more info
notation, recall that these signify the limit superior and limit inferior of a sequence, which are limiting bounds on a sequence (more info  and
and  . So
. So  consists of all the positive terms in
consists of all the positive terms in  and of 0s in the place of the negative terms and
and of 0s in the place of the negative terms and  is the opposite.
is the opposite. would have to converge and if one converged and one diverged then
would have to converge and if one converged and one diverged then  would converge (check this!)
would converge (check this!) of positive terms and of the absolute values of the negative terms in order in
of positive terms and of the absolute values of the negative terms in order in  such that the series
such that the series![P_1 + \cdots P_{m_1} - Q_1 -\cdots - Q_{k_1} + \\[1mm] P_{m_1+1} + \cdots + P_{m_2} - Q_{k_1+1} - \cdots - Q_{k_2} + \cdots](https://s0.wp.com/latex.php?latex=P_1+%2B+%5Ccdots+P_%7Bm_1%7D+-+Q_1+-%5Ccdots+-+Q_%7Bk_1%7D+%2B+%5C%5C%5B1mm%5D+P_%7Bm_1%2B1%7D+%2B+%5Ccdots+%2B+P_%7Bm_2%7D+-+Q_%7Bk_1%2B1%7D+-+%5Ccdots+-+Q_%7Bk_2%7D+%2B+%5Ccdots&bg=ffffff&fg=000000&s=1 "P_1 + \cdots P_{m_1} - Q_1 -\cdots - Q_{k_1} + \\[1mm] P_{m_1+1} + \cdots + P_{m_2} - Q_{k_1+1} - \cdots - Q_{k_2} + \cdots")
 so that
so that  and
and  . Then let
. Then let  and
and  be the smallest integers such that
be the smallest integers such that and
and  (let
(let  )
) diverge.
diverge. and
and  so that
so that  and
and  .
. with integer values. We seek to find a rectangular subarray of M whose sum of elements is maximized.
with integer values. We seek to find a rectangular subarray of M whose sum of elements is maximized.
") as we would have to examine all subarrays of M and build up the sums incrementally. A cleverer way is by using Dynamic Programming in Kadane’s algorithm.
as we would have to examine all subarrays of M and build up the sums incrementally. A cleverer way is by using Dynamic Programming in Kadane’s algorithm.") denote the maximum sum subarray of M ending at index
denote the maximum sum subarray of M ending at index  . We can easily see how the following recursive formula holds:
. We can easily see how the following recursive formula holds:![P(i) = \left\{ \begin{array}{ll} M[i], &\text{if } i=0 \\ \max\{M[i], M[i]+P(i-1)\}, & \text{otherwise} \end{array} \right.](https://s0.wp.com/latex.php?latex=P%28i%29+%3D+%5Cleft%5C%7B+%5Cbegin%7Barray%7D%7Bll%7D+M%5Bi%5D%2C+%26%5Ctext%7Bif+%7D+i%3D0+%5C%5C+%5Cmax%5C%7BM%5Bi%5D%2C+M%5Bi%5D%2BP%28i-1%29%5C%7D%2C+%26+%5Ctext%7Botherwise%7D+%5Cend%7Barray%7D+%5Cright.+&bg=ffffff&fg=000000&s=2 "P(i) = \left\{ \begin{array}{ll} M[i], &\text{if } i=0 \\ \max\{M[i], M[i]+P(i-1)\}, & \text{otherwise} \end{array} \right.")
") .
. and
and  be two columns of M. Then we want to constructively construct an array T such that T[i] holds the sum of all values of row i of M between the two columns. On T we run Kadane’s algorithm for 1D to get our solution. This algorithm runs in
be two columns of M. Then we want to constructively construct an array T such that T[i] holds the sum of all values of row i of M between the two columns. On T we run Kadane’s algorithm for 1D to get our solution. This algorithm runs in ") over the
over the ") brute force approach.
brute force approach.